[쇼핑데이터 ML] 3-1. 데이터 전처리(2)
2. 결측치 처리
2.1 Pattern
- Random
- Rule
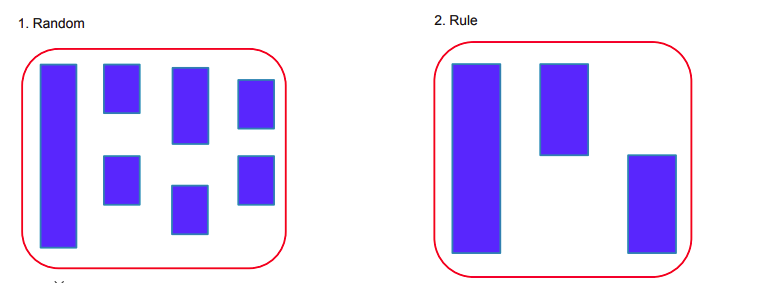
- 실제 데이터의 결측치에 어떤 패턴이 존재하는지 직접 데이터를 보며 확인하는 것이 가장 바람직
-> 결측치 패턴을 heatmap으로 그려보는 것이 좋음
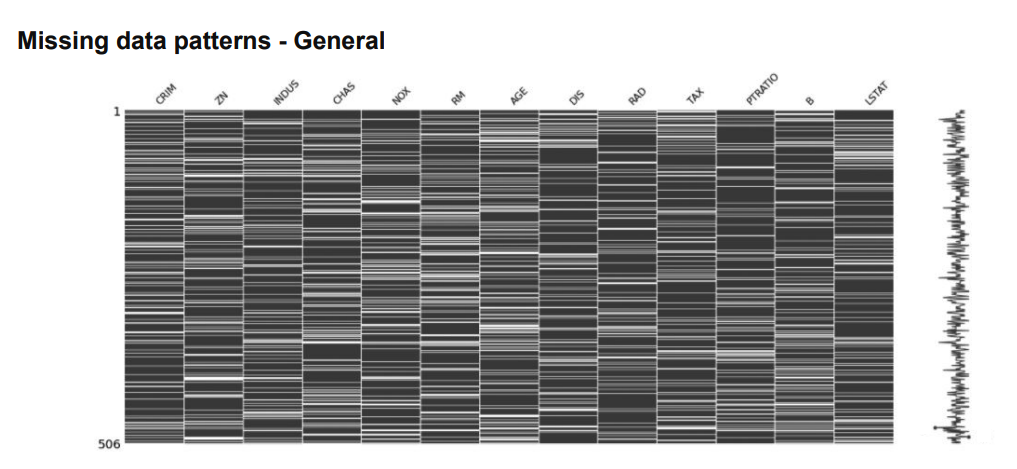
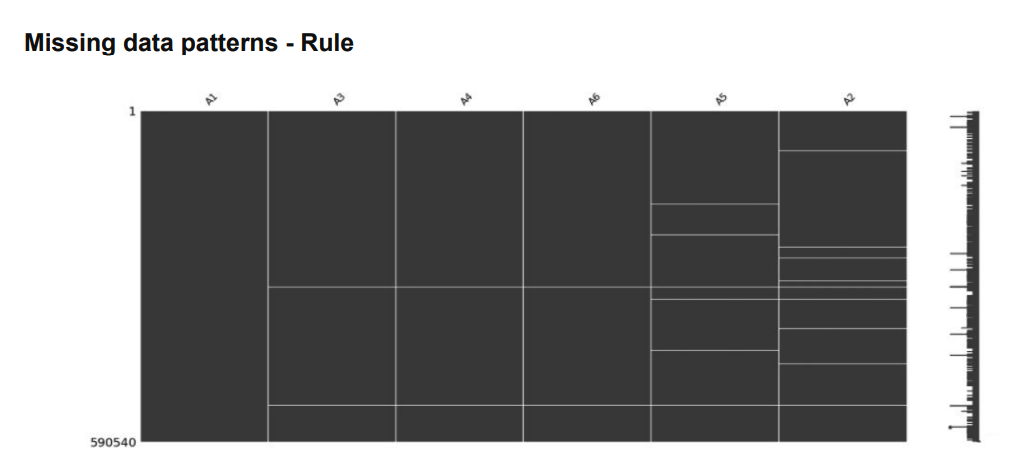
2.2 Univariate
1. 제거
- 결측치 Data Point 제거
- 데이터가 충분히 많지 않으면 불가능
- 테스트 데이터에 결측치 있는 경우도 불가능
- 결측치가 있는 변수(피처) 제거
- 결측치가 너무 많을 경우
2. 평균값 삽입
3. 중위값 삽입
4. 상수값 삽입
-> 모두 본 데이터의 분포가 망가지지 않는 다는 전제 하에 수행되어야 함
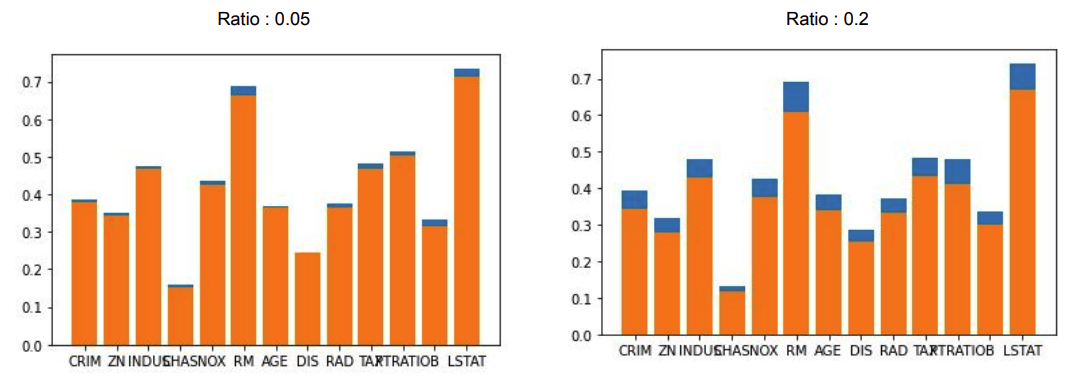
- x축: 변수 / y축: 상관계수
- 결측치 비율
- 비율이 크지 않을 경우 어떤 방법을 사용해도 상관관계에 큰 영향을 주진 않음
- 비율이 클 경우 데이터 분포와 상관관계에 영향 줄 수 있음
5. Modeling을 통해 결측치 채우기
-
회귀 분석
-
KNN nearest

- Color Map
- 파란색 : 결측치 채우기 전
- 주황/노랑 : 결측치 채운 후
- Axis
- left : variables - correlation : bar plot
- right : LSTAT(variable) - count : dist plot
- 특징
- 단변량 통계를 활용한 단순 결측치 삽입보다 변수의 분포가 잘 보존
- 기존에 갖고 있던 변수와 - Target의 상관관계도 잘 유지됨
2.3 Multivariate (합리적 접근법)
데이터의 의미를 보고 채우는 방법- 통계적 접근보다 더 유의미할 수 있음

3. 이상치 처리
- 선형 모델
- 모델 성능에 큰 영향
- 이상치 처리가 중요
- 모델 성능에 큰 영향
- 트리 모델
- 선형 모델보다는 덜 영향 받음
- 모델의 성능을 보고 이상치 처리 여부 판단해도 됨
- 선형 모델보다는 덜 영향 받음
-
주의할 점
-
조심스럽게 처리해야 함
-
잘못하면 모델의 성능에 큰 영향을 끼칠 수 있음…
-
3.1 이상치란?
- 일반적인 데이터와 크게 다른 데이터

- upper example
- 이상치 제거 전 상관관계 0.95
- 이상치 제거 후 랜덤하게 흐트러져 있음이 확인 됨
- X, Y는 서로 상관관계가 거의 없음
- lower example
- 이상치 없을 경우 Linear한 관계 잘 도출됨
- 이상치가 있을 경우 관계 왜곡
3.2 이상치 탐색
1. Z-Score
2. IQR
3.3 이상치 처리 관점
1. 정성적인 측면
- 이상치 발생 이유
- 이상치의 의미

- 신축일수록 아파트 가격이 올라감
- 1970~1980년대 지어진 아파트들 이상치 존재
- 재개발 / 재건축 이슈가 있는지 확인
- 위 변수를 추가로 사용하면 성능 향상 가능
- 1970~1980년대 지어진 아파트들 이상치 존재
2. 성능적인 측면
- Train, Test 데이터에서의 분포
- Test 데이터에 있는 이상치라면 Train 데이터에서 제거하지 않는 것이 바람직
- 모델의 성능 하락의 원인
- Test 데이터에 있는 이상치라면 Train 데이터에서 제거하지 않는 것이 바람직
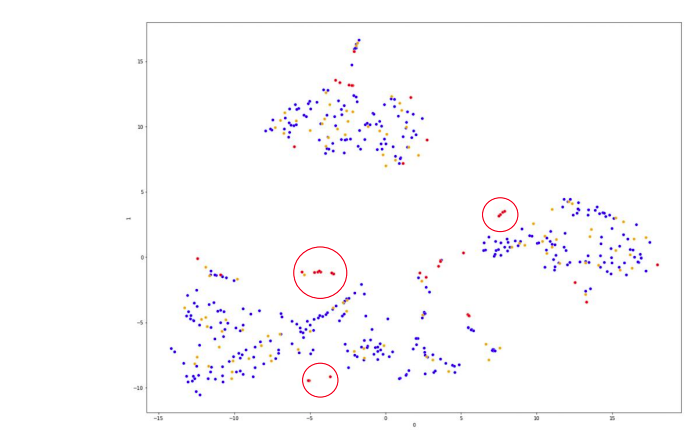
- Chart
- 데이터의 차원을 축소한 2차원 Scatter Chart
- Color Map
- blue : Training Data
- yellow : Test Data
- red : Z-Score based Outlier detection
- 이상치 - Training Data 겹치는 부분 있음
- But, Test Data와는 크게 겹치지 않음
- 이상치 제거하는 것이 성능 향상에 바람직
